分布式tensorflow(一)
Updated:
前言
在了解分布式tensorflow的时候,首先需要了解tensorflow的一些基本概念。
Tensorflow是一个基于图的计算系统,其主要应用于机器学习。
从Tensorflow名字的字面意思可以拆分成两部分来理解:Tensor+flow。
- Tensor:中文名可以称为“张量”,其本质就是任意维度的数组。一个向量就是一个1维的Tensor,一个矩阵就是2维的Tensor。
- Flow:指的就是图计算中的数据流。
当我们想要使用Tensorflow做什么事情的时候,一般需要三个操作步骤:
- 创建Tensor;
- 添加Operations(Operations输入Tensor,然后输出另一个Tensor);
- 执行计算(也就是运行一个可计算的图)。
Tensorflow有个图的概念。
A data flow graph representing a TensorFlow computation.
Operations会添加到图中,作为图的节点。在添加某Operation的时候,不会立即执行该Operation。Tensorflow会等待所有Operation添加完毕,然后Tensorflow会优化该计算图,以便决定如何执行计算。
分布式tensorflow是一个很有意思的idea,分布式系统能帮我们在网络带宽一定的情况下做很多性能的扩展,如Hadoop分布式计算平台,它采用分布式存储的方式来提高读写速度和扩大存储容量。那么distributed tensorflow可以利用分布式来更好的并行利用大量的计算资源来实现数据并行,提高数据吞吐率以及training的速度。整理了一份tensorflow devsubmit的资料以及distributed tensorflow的学习笔记。
这是一篇OSDI的论文中提到的用分布式tensorflow来并行计算和训练模型,从25个GPU,扩展到200个GPU,数据的吞吐量也从500不到,显著提高到2000以上。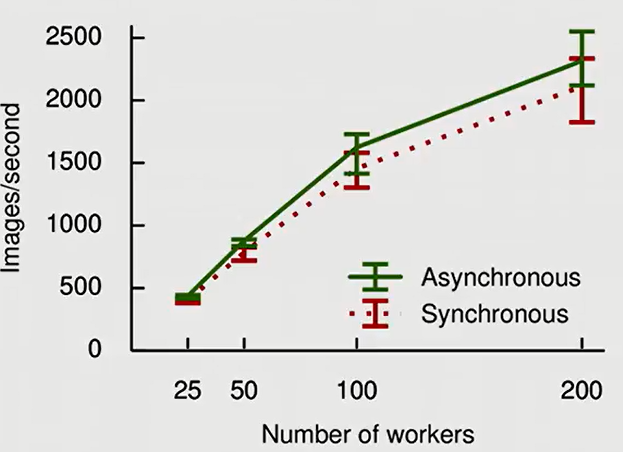
分布式tensorflow的主要概念
之前玩了一阵子Kubernetes, 有一次好奇就在K8S上搭了tensorflow并在一个主节点两个子节点的小集群上并行跑了一个小model,那时候只是把tensorflow on K8S跑通了,并没有深刻理解架构上是怎么实现的。要理解分布式tensorflow可以从几个方面自底向上地学习:
- replicating your model(复制化你的模型)
- Device placement for Variables(如何为参数放置训练资源)
- Sessions and Servers(会话和主服务)
- Fault tolerance(容错设计)
假设我们有一台机器,有CPU设备和GPU设备,我们要在上面跑tensorflow的话,一般用CPU来处理参数,GPU来处理数学计算,如下图所示, 用tf.device来定义每个设备的用途: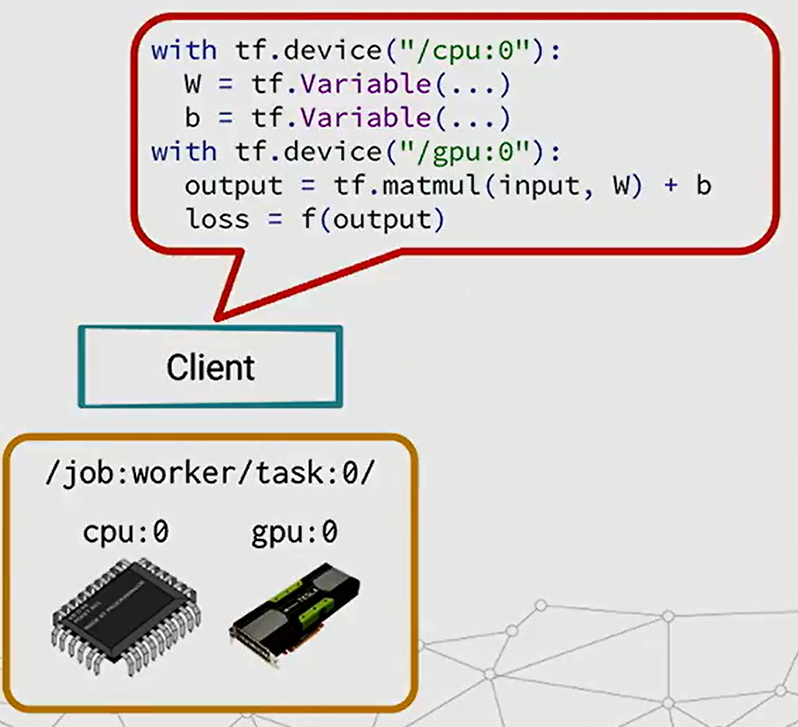
如果我们多了一台机器,只有CPU,我们想要分别用第一台机器的GPU和第二台机器的CPU来做计算,该怎么做?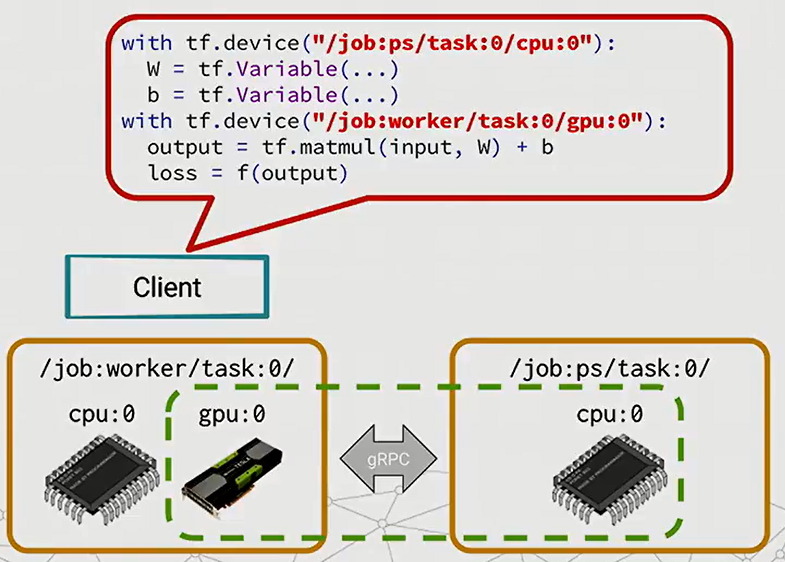
可以看到上图中的python代码,唯一的区别是tf.device处定义的不同。不同的节点之间通过gRPC通信。
分布式资源放置管理
tensorflow的分布式的设计灵感来自于谷歌之前的一个系统——DisBelief。Disbelief中有两个明显不同的进程:
- 一个是PS(parameter servers): PS负责保存和更新所有模型的状态,也就是参数,并根据后面的梯度下降进行更新参数。
- 另一个是worker replicas: Worker则是做集中计算,会计算神经网络的Loss, 并且准确计算梯度。
那么在tensorflow中,设计者也通过一些设计来模仿这个工作模式。Distributed tensorflow也会有PS tasks和Worker tasks。PS tasks负责处理参数变量和更新参数,下图中剩下的工作就是由Worker来实现,前向传播计算,计算loss,后向传播等。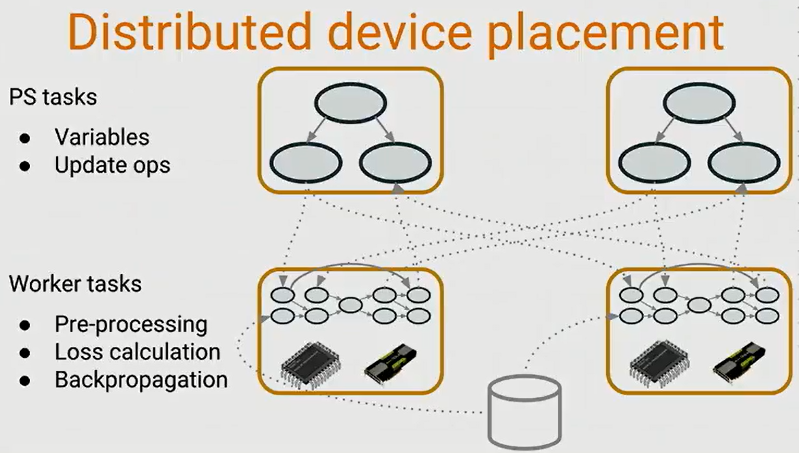
这样看来分布式tensorflow和DisBelief几乎完全一样。它们的最大不同之处在于,在DisBelief中, PS和worker是两个完全不同的程序,而且几乎没有相联,没有共同点,你可以通过完全不同的API来使用它们。
而在Tensorflow中,PS和worker的运行代码完全相同。它们只是你可以发送一点tensorflow图(graph)的服务器,它会对你定义的图进行反应。这样的设计会带来很大的灵活性。
举个栗子:我们也可以对一个PS任务添加GPU来加速参数更新计算,或者我们也可以让worker任务做一些本地存储的工作,存一些cache来防止网络堵塞,又或者我们可以把所有的PS都删掉,只留下worker,只要worker之间的通讯网络足够快,这样就非常灵活。但我们实际的应用中,区分PS和worker可以更好地帮助我们训练一些网络。接下来举一些例子,来看看我们怎么做到的。
- replicating your model(复制化你的模型)
- Device placement for Variables(如何为参数放置训练资源)
- Sessions and Servers(会话和主服务)
- Fault tolerance(容错设计)
一. 模型复制(replicating)
当一个model在单机中可以很好实现的时候,replication可以用来加强分布。基本思想是给一个任务复制很多个副本,每个副本都处理不同的数据子集,也就是数据并行处理计算。
In-graph replication
最简单的一个复制副本的想法叫图内复制(In-graph replication)方法。我们从代码来理解这个方法的实现:
- 首先我们在PS任务中添加变量,这个步骤和之前一样
- 然后把一批输入数据做split处理,分成等量数据块,在循环地分发给worker tasks
- 用tf.device把每个worker task加入子图来计算部分的结果
- 最后把结果整合成最后的loss损失,可以用tensorflow优化器进行优化
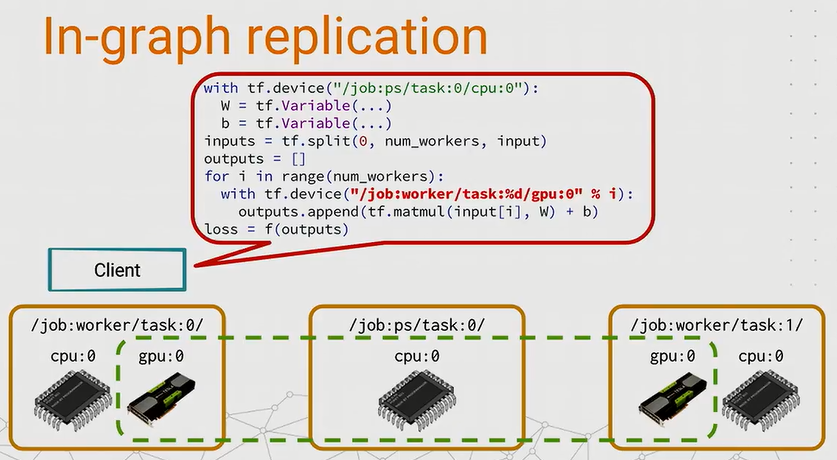
图5
graph内复制思想很简单,也很好实现,不需要修改代码,在少量副本的情况下可以工作得很好,比如利用单机中多个GPU。但当应用在很大的模型时,比如在几百台的机器上运行时,会发现最后的图会变得很大,client之间不能很好地协调工作来建立整个图。因此就提出来另外一个方法————图间复制。
Between-graph replication
跟上一个想法的不同是,图间复制的思想是让每个worker都创建一个图跑一个很小的图计算,然后把非参数的数据放在本地。当在运行多个client时,由中间的PS task来交互client之间的数据变化。听上去很神奇,实现原理是,当有两个worker task时,会创建两个同样名字的变量,然后放在PS中的内存中共享,当一个worker task更新了变量,那个对于另一个task也是可见的,所以这样可以训练得更快。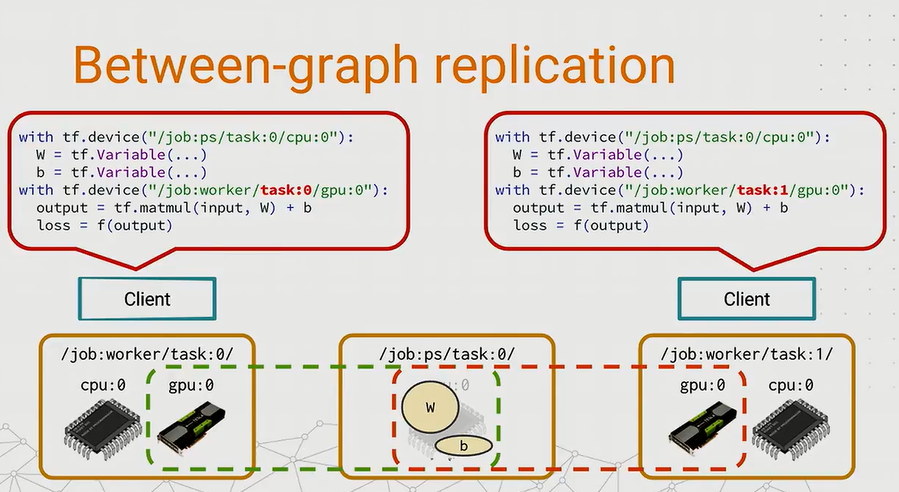
这种变量共享设计就带来另外一个问题:我们如何选择地址来放置我们的变量?因为上一个例子中只有一个PS task,这样把所有的变量用设备字都放置在一个固定设备中固然可行,但有时我们想要实现多于1个的PS task时候怎么办呢?比如我们想要分配变量更新的工作,或者想平衡worker task来取变量时候的网络负载时,很可能就要用到多个PS任务了。接下来就讨论一下变量的放置问题。
二. 根据参数放置设备(Device placement for Variables)
tensorflow有一个神奇的设备函数。我们可以不用把设备字符串传给tf.device,我们可以使用设备函数。我们可以用不同的设备函数来创建更多更加巧妙强大的放置策略。tensorflow已经提供了一些写好的设备函数可以很方便地调用。
Round-robin variables
最简单的一个方法叫tf_train_replica_device_setter方法,它会循环地分配变量,就像创建PS的时候。这个设备函数的优点是,你可以把整个模型建模代码用这个模块包起来。它只影响变量,把它们放在PS任务中,而其他的工作会自动到worker中执行。
这边有一段示例程序展示如何使用,如下图所示,这个程序会把第一个weight权重变量被放在到PS task0,第一个bias偏置变量被放置到PS task1, 接下来第二个weight被放置到PS task2,最后一个回来放到task0中。
这明显不是一个最优的平衡负载放置策略。显然可以有更好的策略可以做得更好,所以tensorflow提供有另一个注重负载平衡的放置策略。
Load balancing variables
有一个简单的贪婪策略叫GreedyLoadBalancingStrategy, 它可以根据参数的内存字节来完成类似在线垃圾收集的工作。根据weight和bias的字节数来放置到内存合适的task中,带来更好的负载平衡。
Partitioned variables
以上讨论的都是很小字节的参数,每个PS task都可以单独处理一个变量。但当遇到超大字节,比如可能是几万MB的数据该如何处理?要解决这个问题,提出一个分割变量的方法。假设你用分隔符创建了一个变量,tensorflow会把这个变量分割成3个部分,分发到3个PS task中。
三. 进程和主服务(Session and Servers)
当我们完成了资源配置后,我们就要开始继续run一个tensorflow的session了。如果你使用以下的代码来运行一个tensorflow的session, tf.Session只能知道本地机器的资源设备。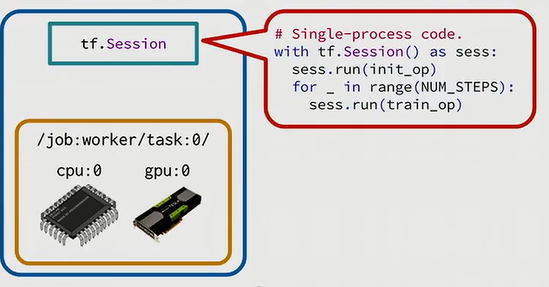
这时候,手头上还有200多台机器想利用起来,该怎么用呢?
答案就是,在每一台机器上起一个tf.train.Server的服务,然后放在一个集群里,整个集群的server会通过网络通信。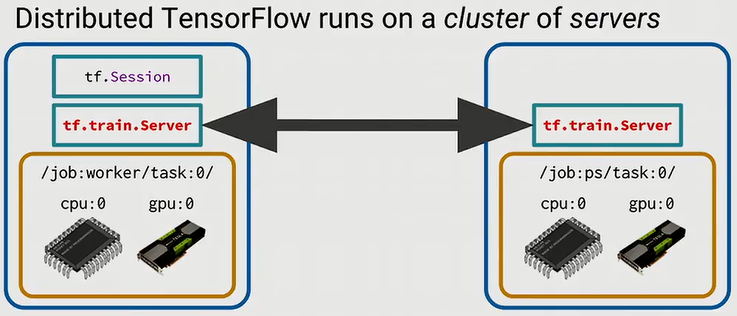
详细看一下如何用代码实现一个worker task。
- 定义一个
ClusterSpec, 用于定义一个集群中的PS, worker分别对应的是哪些机器。这样手动输入很容易出错,所以我们还可以用kubernetes或Mesos这些集群管理框架来管理。后面会出一篇tensorflow on k8s的文章; - 然后创建一个
tensorflow Server,它代表集群里的一个特定任务 - 最后创建一个
Session,一个session可以在集群中的任何一个设备上运行代码。
图12
PS task的代码更加简单,下面这个例子中,PS task只是block在那儿,等待其他Worker节点发给他们的图,步骤也很简单:
- 定义一个
ClusterSpec; - 然后创建一个
tensorflow Server,它代表集群里的一个特定任务 - 最后
server.join()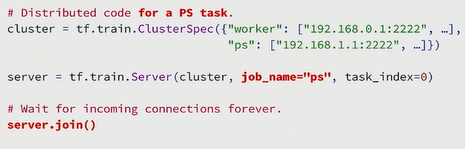
图13
这个server.join()是什么意思?join的代码只有10~15行c++代码,做一些错误检查,并且jion一些线程,所以叫做join。它的作用就是block在那里,等待集群中其他节点的接入。
四. 容错性(Fault tolerance)
Saver
当完成了上面的步骤后,就结束了吗?当你在跑一个耗时很长的分布式training任务的时候,都会有这样的担忧,如Leslie Lamport说过的一句话:
A distributed system is a system where I can’t get my work done because a compuer has failed that I’ve never heared of.
机器总是不知为何就failed掉了,导致整个training不能成功。在长时间的训练任务中,我强烈推荐大家使用saver来不断把参数检查点存储到磁盘上。
tensorflow的分布式功能中有几个点需要强调一下: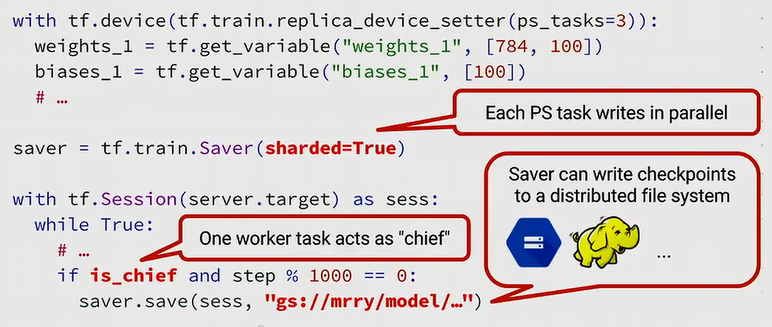
Saver的sharded参数设置为True, 也就是设置分片数据。如上图所示,我们这个例子中有3个PS任务,所以分片为3份来并行写入。- 如果你使用的是图间复制,你可以选择一个或多个worker任务来回应写入要求。一般来说我们用woker task0来执行一些额为的任务,因为worker是从0开始计数,所以总有worker0存在。这个任务我们称为
chief task, 主要负责一些重要的维护任务,比如写入检查点,初始化参数,以及在tensor board中记录一些总结。 Saver现在支持分布式文件系统,比如Google ML, 或者如果你跑在一个Hadoop集群上,你可以写入一个HDFS。
容错性
上面的Saver可以防止运行过程中出错,那么当不幸真的遇到了错误呢?
遇到的错误可以分为以下几种:
最好的情况就是
非Chief的worker task出错了,因为这些task实际上是无状态的。那么当遇到了这种错误,当这样的一个worker task恢复的时候,它会重新与它的PS task中建立连接,并且重新开始之前崩溃过的进程。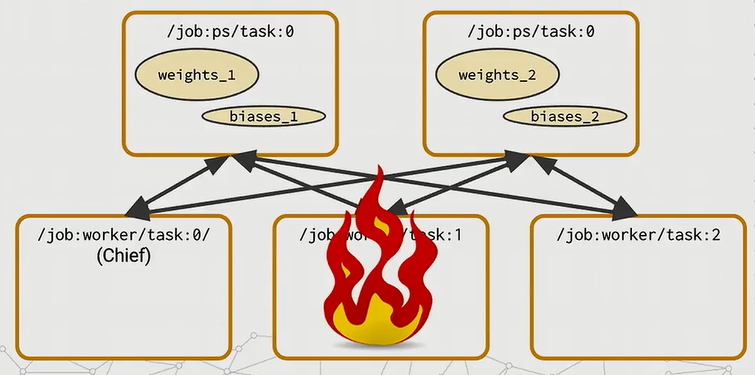
图15 比较差的一种情况就是PS task失败了,那么就有一个麻烦,因为PS task是有状态的,所有的worker task需要依赖他们来发送他们的梯度并且取得新的参数值。所以这种情况下,他们的
chief worker task负责监测这种错误,如果发生了这种错误,chief worker task就打断整个训练,并从上一个检查点恢复所有的PS tasks。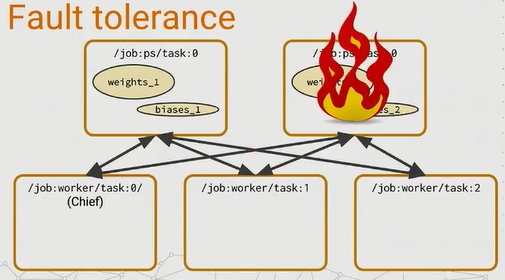
图16 最糟糕的情况就是
chief worker task失败了,因为我们让它负责其他所有的任务,我们就要确保它失败了,能够让集群里所有的任务都回到一个很好的状态。所以我们做的就是打断训练,并在当它恢复了时候从上一个好的检查点恢复。这样的处理方式很简单,但也依赖于机器的健壮性。这里也抛出了一个想法,或许你可以使用一个配置比如Hadoop ZooKeeper 或Etcd来选举chief worker task而不是简单地定义为task0.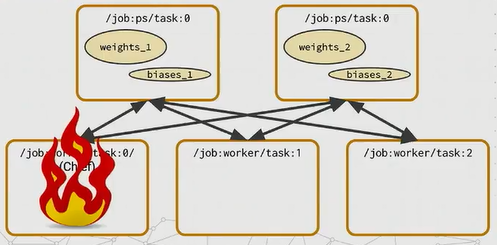
图17
Fault tolerance 的API
下面就来介绍一下tensorflow中的容错性一些API。
- MonitoredTrainingSession:
首先,我们看一下单线程的代码是怎么写的,一般就是初始化参数,或从一个检查点恢复参数:
而使用了MonitoredTrainingSession的代码会自动帮你初始化参数,并且当PS 任务失败会自动恢复。
总结
分布式Tensorflow可以让你很灵活的去扩展你的训练,当你有很多CPU,GPU可以用的时候,当你有一个很巨大的模型要训练的时候,分布式tensorflow就会显得很灵活。
Further reading:
https://tensorflow.org/extend/architecture
https://tensorflow.org/deploy/distributed
https://tensorflow.org/extend/estimators